[Änderung 2022-10-18: Ersetze epsilon durch delta in der Beschreibung
von Beispiel 7 in pgapack]
Viele Optimierungsprobleme beinhalten Randbedingungen die von gültigen
Lösungen erfüllt sein müssen. Ein
Optimierungsproblem mit Randbedingungen wird typischerweise als
nichtlineares Programmierungs-Problem formuliert .
\begin{align*}
\hbox{Minimiere} \; & f_i(\vec{x}), & i &= 1, \ldots, I \\
\hbox{Unter den Bedingungen} \;
& g_j(\vec{x}) \le 0, & j &= 1, \ldots, J \\
& h_k(\vec{x}) = 0, & k &= 1, \ldots, K \\
& x_m^l \le x_m \le x_m^u, & m &= 1, \ldots, M \\
\end{align*}
In diesem Problem gibt es \(n\) Variablen (der Vektor
\(\vec{x}\) hat die Länge \(n\)), \(J\) Ungleich-Bedingungen,
\(K\) Gleichheits-Bedingungen und die Variable \(x_m\) muss im
Bereich \(|x_m^l, x_m^u|\) sein (als Box-Bedingung bezeichnet). Die
Funktionen \(f_i\) heissen Zielfunktionen. Probleme mit mehreren
Zielfunktionen habe ich schon früher in diesem Blog beschrieben.
Im folgenden werde ich einige Begriffe ohne weitere Erklärung verwenden
die in diesem früheren Blogbeitrag eingeführt wurden.
Die Zielfunktionen werden nicht notwendigerweise minimiert (wie in der
Formel angegeben) sondern können auch maximiert werden wenn das Problem
dies verlangt. Die Ungleich-Bedingungen werden auch oft mit einem
\(\ge\) Zeichen formuliert, die Formal kann einfach umgestellt
werden (z.B. durch Multiplikation mit -1) um ein \(\le\) Zeichen zu
verwenden.
Nachdem es recht schwer ist, Gleichheits-Bedingungen zu erfüllen,
besonders wenn diese in nichtlinearen Funktionen der Eingabevariablen
auftreten, werden Gleichheits-Bedingungen oft in Ungleich-Bedingungen
umgewandelt unter Verwendung einer δ‑Umgebung:
\begin{equation*}
-\delta \le h_k(\vec{x}) \le \delta
\end{equation*}
Wobei δ so gewählt wird dass die Lösung gut genug für das zu
lösende Problem ist.
Eine sehr erfolgreiche Methode zur Lösung von Problemen mit
Randbedingungen verwendet eine lexicographische Ordnung von
Randbedingungen und Zielfunktion(en). Lösungskandidaten des Problems
werden zuerst nach verletzten Randbedingungen sortiert (typischerweise
der Summe der Verletzung von Randbedingungen) und dann nach dem Wert der
Zielfunktion(en) . Beim Vergleich von zwei Individuen während der
Selektionsphase des Genetischen Algorithmus gibt es drei Fälle: Wenn
beide Individuen die Randbedingungen verletzen gewinnt das Individuum
mit der kleineren Verletzung der Bedingungen. Wenn ein Individuum keine
Bedingung verletzt, das andere aber schon, gewinnt das Individuum ohne
Verletzung von Randbedingungen. Im letzten Fall dass keines der
Individuen die Bedingungen verletzt, findet ein normaler Vergleich der
Zielfunktionen statt (was vom verwendeten Algorithmus abhängt und ob
maximiert oder minimiert wird). Diese Methode, ursprünglich von Deb
vorgeschlagen ist in PGAPack und im Python Wrapper PGAPy
implementiert.
Mit diesem Algorithmus zur Behandlung von Randbedingungen, werden zuerst
Lösungskandidaten gefunden die keine Randbedingung verletzen bevor der
Algorithmus die Zielfunktionen überhaupt "anschaut". Daher passiert es
dann oft, dass die Suche in einer Region endet wo es keine guten
Lösungen gibt (aber dafür keine Randbedingungen verletzt sind).
Schwierige Probleme, bei welchen dies auftritt, sind oft Probleme mit
Gleichheits-Bedingungen aber es gibt auch andere "schwierige"
Randbedingungen. In einem früheren Blog Post zur
Antennen-Optimierung habe ich geschrieben: "dass der
Optimierungs-Algorithmus Schwierigkeiten hat, überhaupt sinnvolle
Lösungen für die Direktor-Variante zu finden. Nur bei einer handvoll
Experimente war es überhaupt möglich, die obige Pareto-Front zu finden."
In diesem Experiment habe ich 50 Optimierungsläufe durchgeführt und nur
5 davon sind nicht in einem lokalen Optimum steckengeblieben. Etwas
ähnliches passiert bei Problem 7 in Deb's Artikel wo
Gleichheits-Bedingungen verwendet werden. Ich habe dieses als
Beispiel 7 in PGAPack implementiert. Es wird nur eine Lösung nahe dem
(bekannten) Optimum gefunden wenn \(\delta \ge 10^{-2}\) für
alle Gleichheits-Bedingungen ist (ich habe nicht mit verschiedenen
Anfangswerten für den Zufallszahlengenerator experimentiert, es könnte
sein dass man mit einem anderen Startwert bessere Lösungen findet). Im
Artikel verwendet Deb \(\delta = 10^{-3}\) aus dem selben
Grund.
Eine Methode, um dieses Problem zu verbessern, war attraktiv, weil sie
sowohl einfach zu verstehen als auch zu implementieren ist: Takahama und
Sakai haben zuerst mit einer Methode experimentiert um unter gelockerten
Randbedingungen in der Frühphase der Optimierung zu arbeiten, sie
nannten dies einen Genetischen Algorithmus mit α‑Randbedingungen . Die Methode wurde später vereinfacht und als
Optimierung mit ε‑Randbedingungen bezeichnet. Sie kann für
verschiedene Optimierungsalgorithmen verwendet werden, nicht nur für
Genetische Algorithmen und Varianten . Von speziellem Interesse in
diesem Zusammenhang ist die Anwendung der Methode für Differential
Evolution , , aber natürlich kann sie auch für andere Formen von
Genetischen Algorithmen verwendet werden.
Das ε im Namen dieser Methode kann für das δ bei der
Konversion von Gleichheits-Bedingungen in Ungleich-Bedingungen verwendet
werden, ist aber nicht auf diesen Anwendungsfall eingeschränkt.
Während des Optimimierungslaufes wird in jeder Generation ein neuer Wert
für ε berechnet. Der Vergleich von Individuen wie oben skizziert
wird so modifiziert, dass ein Individuum so behandelt wird als verletze
es keine Randbedingung wenn die Verletzung der Randbedingungen kleiner
ist als ε. Wenn also beide Individuen die Randbedingungen um
mehr als ε verletzen gewinnt das Individuum mit der kleineren
Verletzung. Wenn ein Individuum die Bedingungen um weniger als ε
verletzt, das andere aber mehr, gewinnt das erste. Und schließlich wenn
die Verletzung der Randbedingungen bei beiden Individuen kleiner ist als
ε findet der normale Zielfunktions-Vergleich statt.
Dieser letzte Fall ist der Schlüssel zum Erfolg des Algorithmus: Obwohl
die Suche in eine Richtung zu weniger Verletzung der Randbedingungen
fortschreitet, wird gleichzeitig eine gute Lösung bezogen auf die
Zielfunktionenen gefunden.
Der Algorithmus startet mit der Initialisierung von
\(\varepsilon_0\) mit der Summe der Verletzung der Randbedingungen
des Individuums mit dem Index \(\theta\) der nach Verletzung der
Randbedingungen sortierten initialen Population. Dabei ist
\(\theta\) ein Parameter des Algorithmus zwischen 1 und der
Populationsgröße, ein guter Wert ist etwa 20% der Populationsgröße,
was auch der Standardwert in PGAPack ist. In jeder Generation \(t\)
wird \(\varepsilon_t\) berechnet zu:
\begin{equation*}
\varepsilon_t = \varepsilon_0 \left(1-\frac{t}{T_c}\right)^{cp}
\end{equation*}
bis zur Generation \(T_c\). Nach dieser Generation wird ε
auf 0 gesetzt. Der Exponent \(cp\) ist zwischen 2 und 10. Der
Artikel von 2010 empfiehlt zur Generation
\(T_\lambda = 0.95 T_c\) den Wert \(cp = 0.3 cp + 0.7 cp_\min\)
zu setzen, wobei \(cp_\min\) der fixe Wert 3 ist. Der Anfangswert
von \(cp\) wird so gewählt dass zur Generation \(T_\lambda\)
\(\varepsilon_\lambda=10^{-5}\) ist ausser \(cp\) wäre kleiner,
dann wird es auf \(cp_\min\) gesetzt. PGAPack implementiert diese
Empfehlung für \(cp\) als Standard-Einstellung, erlaubt aber das
Setzen von \(cp\) zu Beginn und während der Laufzeit der
Optimierung. Es ist also einfach möglich, andere Änderungen von
\(cp\) zu implementieren – die Standard-Einstellung funktioniert
jedoch recht gut.
Durch Optimierung mit ε Randbedingungen konnten in meinen
Experimenten die Gleichheits-Bedingungen in Beispiel 7 von Deb mit
einer Genauigkeit von \(10^{-6}\) approximiert werden, siehe die
Variable epsilon_generation im optimizer Beispiel.
Wird der antenna-optimizer mit ε‑generation 50 gestartet
(das ist der \(T_c\) aus obigem Algorithmus) bleibt der Algorithmus
nur in einem einzigen Fall im lokalen Optimum stecken, alle anderen
Fälle finden gute Lösungen:
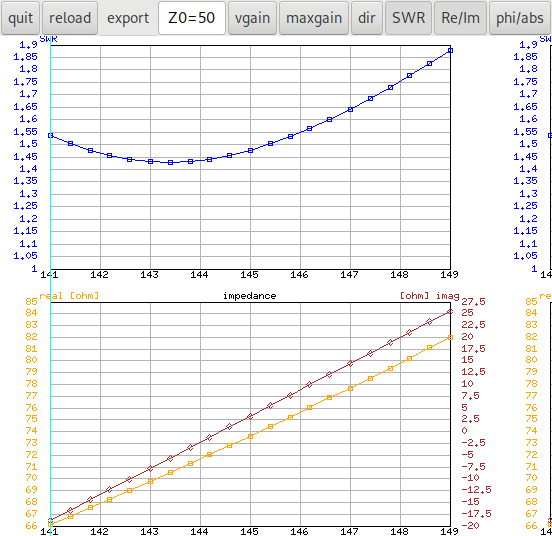
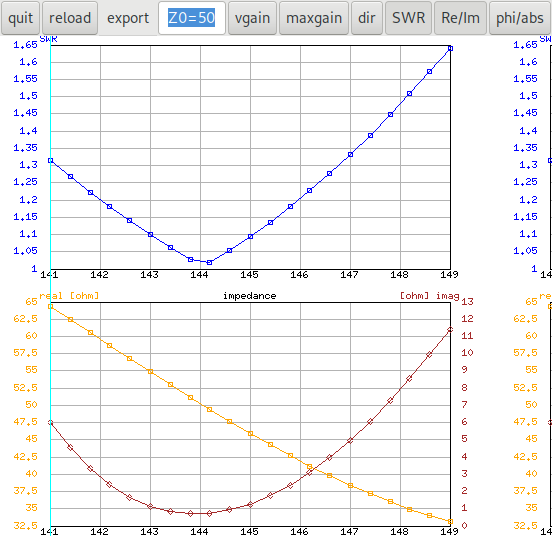
In dieser Grafik sind alle Lösungen von einem Optimierungslauf die von
den Lösungen eines anderen Laufs dominiert werden in Schwarz
eingezeichnet. Wir sehen dass die Daten von Lauf 16 keine
nicht-dominierte Lösung beigetragen haben (auf der rechten Seite in der
Legende fehlt die Nummer 16). In der Grafik kann man die dominierten
Lösungen aus der Anzeige nehmen indem man auf den schwarzen Kreis in der
Legende klickt.
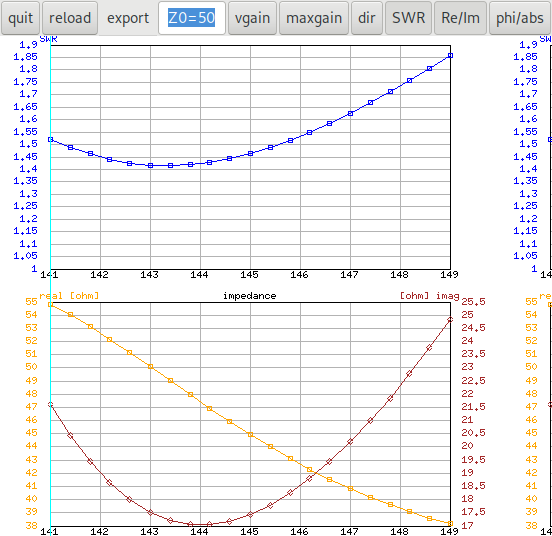
Wenn der Parameter ε‑generation für den Lauf der im lokalen
Optimum geendet hat auf 60 erhöht wird, findet auch der Lauf mit
Zufallszahlen-Startwert 16 eine Lösung:
Es ist auch sichtbar dass die Lösungen für alle Experimente ziemlich gut
(weil nahe an der Pareto-Front) sind. Der schwarze "Schatten" der
dominierten Lösungen ist ziemlich nahe an der wirklichen Pareto-Front
und ist gut genug um mit einem einzigen Optimierungslauf ausreichend
gute Lösungen zu finden.